Redis 布隆过滤器
1、布隆过滤器
内容参考:https://www.jianshu.com/p/2104d11ee0a2
1、数据结构
布隆过滤器是一个BIT数组,本质上是一个数据,所以可以根据下标快速找数据
2、哈希映射
1、布隆需要记录见过的数据,这里的记录需要通过hash函数对数据进行hash操作,得到数组下标并存储在BIT 数组里记为1。这样的记录一个数据只占用1BIT空间
2、判断是否存在时:给布隆过滤器一个数据,进行hash得到下标,从BIT数组里取数据如果是1 则说明数据存在,如果是0 说明不存在
3、精确度
hash算法存在碰撞的可能,所以不同的数据可能hash为一个下标数据,故为了提高精确度就需要 使用多个hash 算法标记一个数据,和增大BIT数组的大小
也是因为如此,布隆过滤器判断为【数据存在】 可能数据并不存在,但是如果判断为【数据不存在】那么数据就一定是不存在的。
4、例子
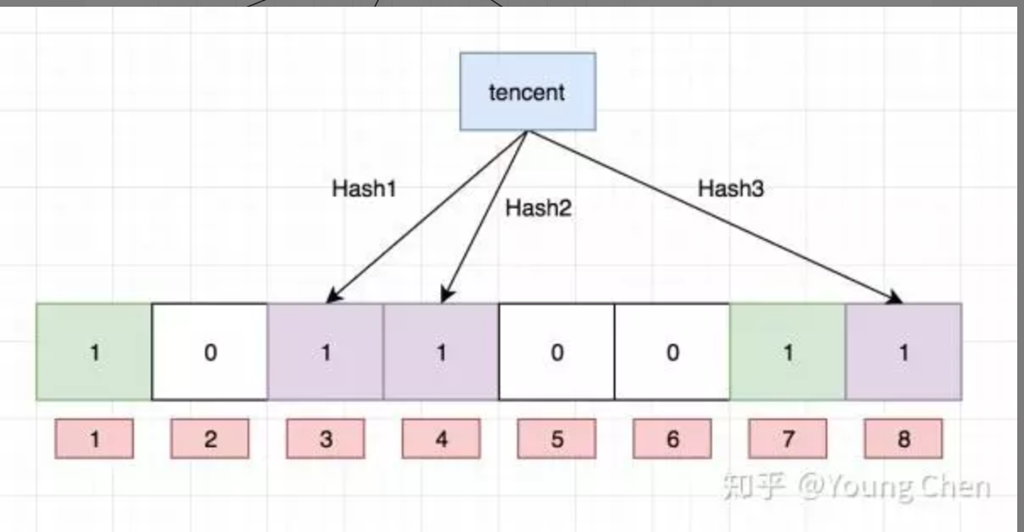
下图映射 baidu字样到布隆过滤器中,用了三个不同的hash函数 3BIT 判断一个数据,BIT数组大小为8
哈希函数返回 1、4、7
我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:
以下 4 位置发生了hash碰撞
5、如何选择哈希函数个数和布隆过滤器长度
显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
6、不支持删除
布隆过滤器只能插入数据判断是否存在,不能删除,而且只能保证【不存在】判断绝对准确
以上不难看出如果给数组的每个BIT位上加一个计数器,插入的时候+1 删除的时候 –1 就可以实现删除。
但是加计数器的实现是有问题的:
由于hash碰撞问题,布隆过滤器不能准确判断数据是否存在,就不能随意删除。其次计数器的回绕问题也需要考虑。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2、给redis安装布隆过滤器模块
1、下载:
地址:https://github.com/RedisBloom/RedisBloom
下载ZIP 文件,上传到linux
RedisBloom-master.zip
2、解压编译
命令:
unzip RedisBloom-master.zip
cd RedisBloom-master
make
扫行完以上命令 后文件夹内生成一个文件名为:redisbloom.so
3、启动redis 时加载该模块
命令:
redis-server redis-6381.conf --loadmodule /zjl/software/RedisBloom-master/redisbloom.so
3、验证
1、链接redis
命令:
redis-cli –a zjl123
2、测试布隆过滤
命令:
bf.add zjl 123
bf.exists zjl 123 #返回 1 ,说明存在值
bf.exists zjl 321 #返回 0, 说明不存在该值
3、准确率
Redis中有一个命令可以来设置布隆过滤器的准确率:
bf.reserve zjl 0.01 100
bf.reserve 有三个参数,分别是 key, error_rate 和 initial_size 。
错误率越低,需要的空间越大。
initial_size 参数表示预计放 入的元素数量,当实际数量超出这个数值时,误判率会上升。
所以需要提前设置一个较大的数值避免超出导致误判率升高。
如果不使用 bf.reserve,默认的 error_rate 是 0.01,默认的 initial_size 是 100。
布隆过滤器的 initial_size 估计的过大,会浪费存储空间,估计的过小,就会 影响准确率,
用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上 一定的冗余空间以避免实际元素可能会意外高出估计值很多。
布隆过滤器的 error_rate 越小,需要的存储空间就越大,对于不需要过于精确 的场合, error_rate 设置稍大一点也无伤大雅。
比如在新闻去重上而言,误判 率高一点只会让小部分文章不能让合适的人看到,
文章的整体阅读量不会因为这 点误判率就带来巨大的改变。
4、项目中使用
1、redis布隆过滤器
没有找到jedis 支持bloom过滤器 命令的版本,只找到了另外一个JAR包的支持,但是也不太好用,没弄明白如何添加密码连接
引入包
<dependency> <groupId>com.redislabs</groupId> <artifactId>jrebloom</artifactId> <version>1.0.2</version> </dependency>JAR包里只有三个类,对连接方式 和 数据类型 的支持都不够
代码:
Client client = new Client(redisProperties.getHost(), redisProperties.getPort(), 10000, 100); client.add("zjl", "123"); boolean zjl = client.exists("zjl", "123"); System.out.println(zjl);2、Guava中的BloomFilter
google的guava包中提供了BloomFilter类,直接用的是服务器内存
导入包
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>22.0</version> </dependency>代码:
private static int size = 1000000; private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), size, 0.0001); public void test2() { String aa = "zjl"; bloomFilter.put(aa); System.out.println(bloomFilter.mightContain(aa)); }3、自已实现布隆过滤器
java 有bitSet数组,hash函数可以自己手动实现
自己手写是可以实现布隆过滤器的,在此不做研究。
原文地址:https://www.cnblogs.com/happydreamzjl/p/11834277.html
- Angular开发实践(七): 跨平台操作DOM及渲染器Renderer2
- Leetcode-Easy 121. Best Time to Buy and Sell Stock
- MongoDB初识
- Python的md5和sha1加密
- LinkedHashSet 源码分析
- Day2下午解题报告
- python获取打开网站的状态码
- 【关关的刷题日记57】Leetcode 101. Symmetric Tree
- FreeBuf官网发布《简易Python Selenium爬虫实现歌曲免费下载》
- HashSet 源码分析
- Angular开发实践(五):深入解析变化监测
- 【关关的刷题日记58】Leetcode 112 Path Sum
- 学大伟业Day解题报告
- Python数据增强(data augmentation)库--Augmentor 使用介绍
- JavaScript 教程
- JavaScript 编辑工具
- JavaScript 与HTML
- JavaScript 与Java
- JavaScript 数据结构
- JavaScript 基本数据类型
- JavaScript 特殊数据类型
- JavaScript 运算符
- JavaScript typeof 运算符
- JavaScript 表达式
- JavaScript 类型转换
- JavaScript 基本语法
- JavaScript 注释
- Javascript 基本处理流程
- Javascript 选择结构
- Javascript if 语句
- Javascript if 语句的嵌套
- Javascript switch 语句
- Javascript 循环结构
- Javascript 循环结构实例
- Javascript 跳转语句
- Javascript 控制语句总结
- Javascript 函数介绍
- Javascript 函数的定义
- Javascript 函数调用
- Javascript 几种特殊的函数
- JavaScript 内置函数简介
- Javascript eval() 函数
- Javascript isFinite() 函数
- Javascript isNaN() 函数
- parseInt() 与 parseFloat()
- escape() 与 unescape()
- Javascript 字符串介绍
- Javascript length属性
- javascript 字符串函数
- Javascript 日期对象简介
- Javascript 日期对象用途
- Date 对象属性和方法
- Javascript 数组是什么
- Javascript 创建数组
- Javascript 数组赋值与取值
- Javascript 数组属性和方法
- 多系列数据核密度图
- leetcode树之二叉树的层平均值
- 大型项目技术栈第二讲 ES6(ECMAScript 6.0)的使用
- 大型项目技术栈第三讲 ztree的使用
- JavaWeb新手训练经典项目 & 半小时高效开发 & 海量知识点涵盖 = 从这里开始
- Java反射_笔记分享
- Java注解详细总结
- 文档驱动 —— 表单组件(六):基于AntDV的Form表单的封装,目标还是不写代码
- 这就是你日日夜夜想要的docker!!!---------Docker资源控制--Cgroup
- 2020-09-26:请问rust中的&和c++中的&有哪些区别?
- python在Keras中使用LSTM解决序列问题
- python使用MongoDB,Seaborn和Matplotlib文本分析和可视化API数据
- 用于NLP的Python:使用Keras进行深度学习文本生成
- 用Python的Numpy求解线性方程组
- python用于NLP的seq2seq模型实例:用Keras实现神经机器翻译