Power BI Power Query 排名1 非连续排名
如下图所示,我有100个分数的数值,现需要对其进行排名处理。很久之前我有写过一篇有关Access里排名处理方式的博文Access SQL实现连续及不连续Rank排名,这一次我将其转换为使用Power Query来进行类似的排名操作。
{kind=link}
首先我们来实现非连续排名,非连续排名最终排出来的名次的数字是非连续的,假如第1名1人,第2名有2人,那么名次为3的人事不存在的,而只有从第4名开始。这种模式的计算逻辑是:对于某一个得分而言,其名次为大于当前分数的所有人的个数+1
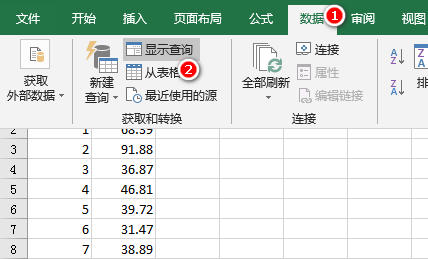
1、首先我们将Excel表数据导入到Power Query管理器中,选择表数据区域,然后依次点击“数据/从表格”,弹出的对话框直接点确认
{kind=link}
{kind=link}
{kind=link}
2、接下来依次点击“添加列/自定义列”,我们首先借助于这个自定义列来为每一行获取一个子表,该子表包含了所有比当前行的分值大的所有行。
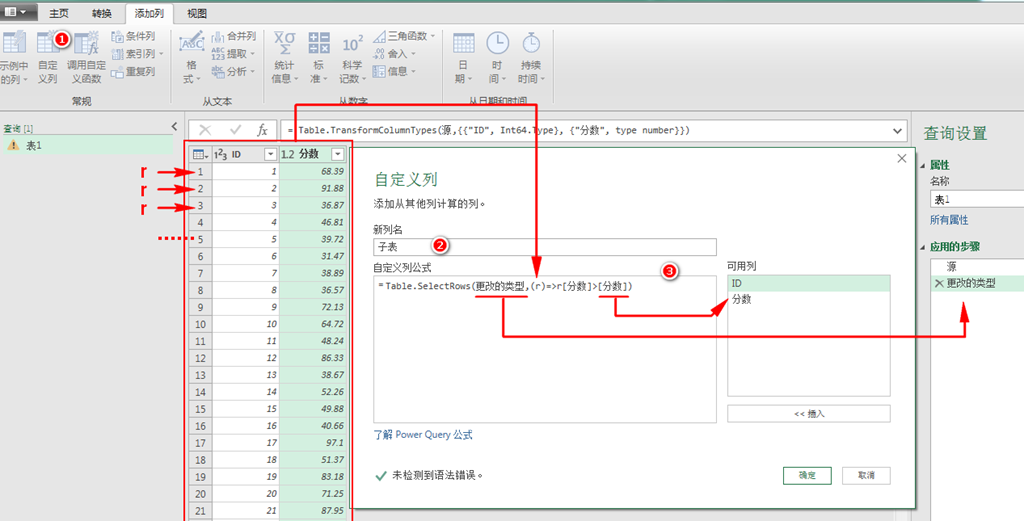
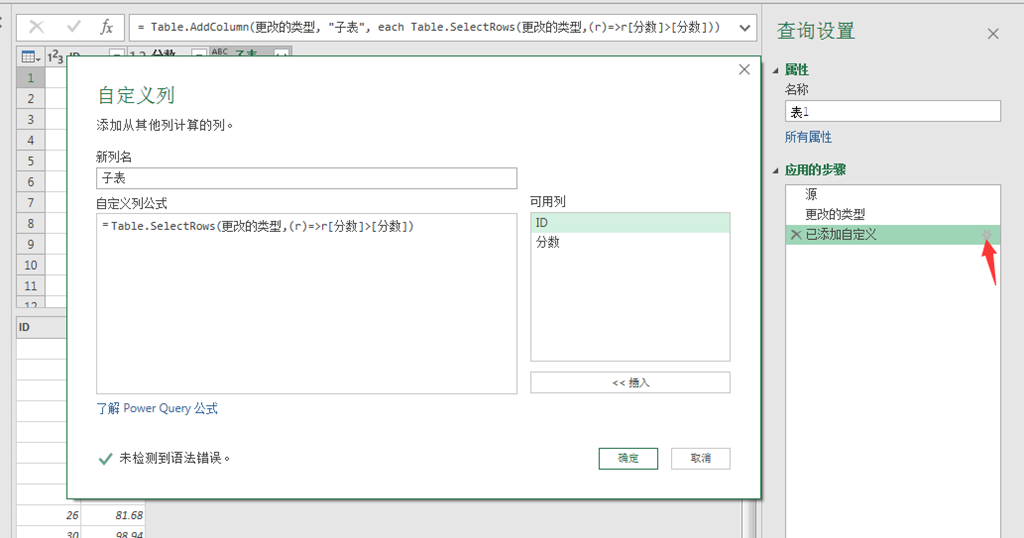
在自定义列窗体中的配置如下图所示,其中的公式为:
=Table.SelectRows(更改的类型,(r)=>r[分数]>[分数])
{kind=link}
说明下公式:
1、使用Table.SelectRows函数来挑选出表中的行
2、Table.SelectRows函数的第1个参数:指明从哪个表里挑选数据,这个表是上一个步骤得到的结果,上一个步骤就是右侧查询设置步骤清单中的“更改的类型”
3、Table.SelectRows函数的第2个参数:该参数是一个lambuda函数表达式,该函数表达式将会被逐行应用到Table.SelectRows函数的第1个参数表的每一行之上。
(r) :这部分是lambuda函数的参数部分,其中的r是参数的名称,你可以使用任何字母,它表示的就是遍历参数表的行,你需要区分它与整个公式计算所在的当前行之间的差异。
拿计算列的第1行为例,当前自定义列的公式所在的行是第1行,而这个lambuda函数将会遍历表的所有行,每次都取一行的值与当前行(第1行)的分数比较,我这里的表有100行,所比较操作就有100次;
后面计算列的所有行都是相同处理,所以需要运算的次数为100*100=10000次。
=>:箭头符号,用来分隔lambuda函数的参数部分和逻辑代码部分
r[分数]>[分数]:lambuda函数的逻辑代码部分,该部分需要返回一个逻辑值,以便于Table.SelectRows函数判定是否需要挑选(筛选)出表中的行,返回结果为真时,表示挑选出来,否则过滤掉改行
其中的r[分数]表示的取当前遍历行中的分数列的值,而大于符号后面的[分数]表示的是自定义列公式所处行中的分数列的值
关于为何使用的是r[分数]来获取分数列的值,而不是使用r{[分数]}来访问这个值,是因为表(Table)中的行其数据类型是记录(Record),关于列表、表和记录数据类型及其访问子元素的方法我在Power BI Power Query 认识M语言中的结构性数据的博文里有说明,如果你不清楚,请先阅读下这篇文章。
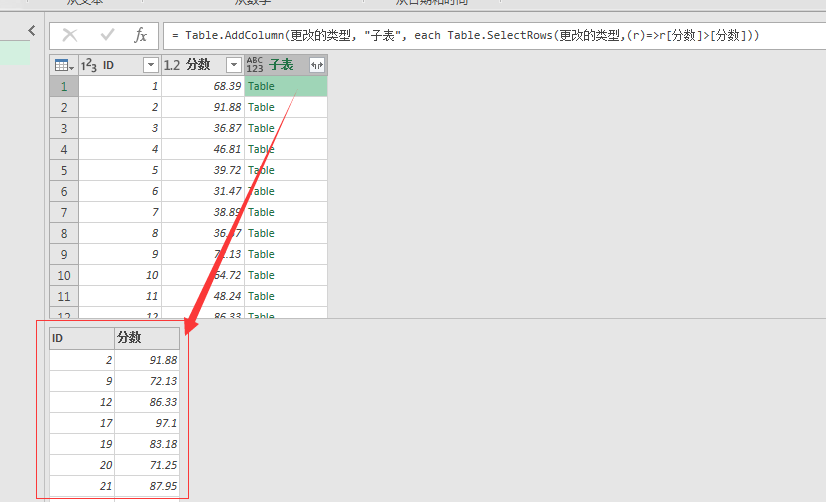
下图是添加自定义列“子表”之后的运行结果,我们可以点击第1行,底部就会加载该子表的数据
{kind=link}
注意:不要点在哪个Table文字上,而是点在右侧空白区域里,点在文字上,PQ将会认为你是要新加一个步骤查看该子表的数据了
接下来就需要将子表中的行统计一下,计算出总行数,并将该数字+1即可得出排名了,下面我们直接在前面的公式上修改
1、在右侧找到最后的操作步骤,右侧有一个齿轮图表,点击一下它,就可以重新弹出“自定义列”对话框
{kind=link}
2、输入如下所示的公式,点击确定按钮后,会看到如下面右侧图片所示的排名结果。
=Table.RowCount(Table.SelectRows(更改的类型,(r)=>r[分数]>[分数]))+1{kind=link}
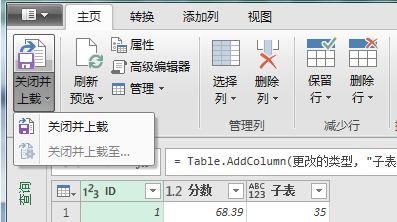
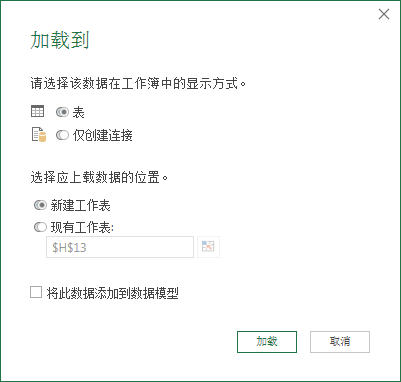
3、依次点击“主页/关闭并上载至”,依次选择“表/新建工作表”,点击加载按钮后,将我们的排名查询加载到Excel中,后续原始数据变动时,我们只需要刷新一下即可得到新的排名
{kind=link}
{kind=link}
原文地址:https://www.cnblogs.com/alexywt/p/11393638.html
- Java中Optional使用注意事项
- 使用awk来解析dump文件 (73天)
- IntelIj IDEA运行JUnit Test OutOfMemoryError
- git pull fails “unable to resolve reference” “unable to update local ref”
- 使用dropwizard(5)--加入swagger
- 使用hint来调优sql语句(72天)
- 用R语言对城管事件数据分析
- 使用dropwizard(4)-加入测试-jacoco代码覆盖率
- goldengate学习-安装篇(71天)
- 使用dropwizard(6)-国际化-easy-i18n
- 配置不同环境下启用swagger,在生产环境关闭swagger
- 使用ControllerAdvice注意事项,Ambiguous @ExceptionHandler method mapped for [class org.springframework.web.
- rac节点无法启动ORA-29702的问题及分析(70天)
- SpringMVC,SpringBoot文件下载
- JavaScript 教程
- JavaScript 编辑工具
- JavaScript 与HTML
- JavaScript 与Java
- JavaScript 数据结构
- JavaScript 基本数据类型
- JavaScript 特殊数据类型
- JavaScript 运算符
- JavaScript typeof 运算符
- JavaScript 表达式
- JavaScript 类型转换
- JavaScript 基本语法
- JavaScript 注释
- Javascript 基本处理流程
- Javascript 选择结构
- Javascript if 语句
- Javascript if 语句的嵌套
- Javascript switch 语句
- Javascript 循环结构
- Javascript 循环结构实例
- Javascript 跳转语句
- Javascript 控制语句总结
- Javascript 函数介绍
- Javascript 函数的定义
- Javascript 函数调用
- Javascript 几种特殊的函数
- JavaScript 内置函数简介
- Javascript eval() 函数
- Javascript isFinite() 函数
- Javascript isNaN() 函数
- parseInt() 与 parseFloat()
- escape() 与 unescape()
- Javascript 字符串介绍
- Javascript length属性
- javascript 字符串函数
- Javascript 日期对象简介
- Javascript 日期对象用途
- Date 对象属性和方法
- Javascript 数组是什么
- Javascript 创建数组
- Javascript 数组赋值与取值
- Javascript 数组属性和方法
- 弄懂这 5 个问题,拿下 Python 迭代器!
- 一天一大 leet(跳水板)难度:简单-Day20200708
- 百度一二三面!喜提提起批offer!别问,问就是牛逼!
- 一天一大 leet(计算右侧小于当前元素的个数)难度:困难-Day20200711
- Spring 下,关于动态数据源的事务问题的探讨
- 面试再问 HashMap,求你把这篇文章发给他!
- FestIN:一款功能强大的S3 Buckets数据内容搜索工具
- 一天一大 leet(地下城游戏)难度:困难-Day20200712
- 【MongoDB】mongodb4.4版本新特性
- 一天一大 leet(数组中的第 K 个最大元素)难度:中等 DAY-29
- 线程之生产者消费者模式
- Redis学习笔记 -- 2
- 一天一大 leet(单词拆分)难度:中等 DAY-25
- 多线程必考的「生产者 - 消费者」模型,看乔戈里这篇文章就够了
- 一天一大 leet(三角形最小路径和)难度:中等-Day20200715