kafka设计要点之高吞吐量
kafka设计的目标之一就是高吞吐量。除了最基础的将一个topic划分为多个partition外,还从以下各个方面优化。
kafka broker端为了提高吞吐量:实现顺序读写磁盘、利用page cache,将文件数据映射到内存,利用sendfile网传时socket通信时直接读取内存区域(减少操作系统上下文切换、零拷贝提速);
producer端,将消息buffer起来,当消息的条数达到一定阀值时(一定数量或时间),批量发送给broker;
consumer,批量fetch多条消息.通过配置到达一定阈值时(一定数量或时间),批量从broker拉取信息;
对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制减少网传数据量;压缩需要消耗少量的CPU资源,可以将任何在网络上传输的消息都经过压缩.kafka支持gzip/snappy等多种压缩方式。
顺序写磁盘
根据《一些场景下顺序写磁盘快于随机写内存》所述,将写磁盘的过程变为顺序写,可极大提高对磁盘的利用率。
Kafka的整个设计中,Partition相当于一个非常长的数组,而Broker接收到的所有消息顺序写入这个大数组中。同时Consumer通过Offset顺序消费这些数据,并且不删除已经消费的数据,从而避免了随机写磁盘的过程。
由于磁盘有限,不可能保存所有数据,实际上作为消息系统Kafka也没必要保存所有数据,需要删除旧的数据。而这个删除过程,并非通过使用“读-写”模式去修改文件,而是将Partition分为多个Segment,每个Segment对应一个物理文件,通过删除整个文件的方式去删除Partition内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
通过如下代码可知,Kafka删除Segment的方式,是直接删除Segment对应的整个log文件和整个index文件而非删除文件中的部分内容。
1 | /** |
充分利用Page Cache
使用Page Cache的好处如下
- I/O Scheduler会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非JVM内存)。如果使用应用层Cache(即JVM堆内存),会增加GC负担
- 读操作可直接在Page Cache内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过Page Cache)交换数据
- 如果进程重启,JVM内的Cache会失效,但Page Cache仍然可用
Broker收到数据后,写磁盘时只是将数据写入Page Cache,并不保证数据一定完全写入磁盘。从这一点看,可能会造成机器宕机时,Page Cache内的数据未写入磁盘从而造成数据丢失。但是这种丢失只发生在机器断电等造成操作系统不工作的场景,而这种场景完全可以由Kafka层面的Replication机制去解决。如果为了保证这种情况下数据不丢失而强制将Page Cache中的数据Flush到磁盘,反而会降低性能。也正因如此,Kafka虽然提供了flush.messages和flush.ms两个参数将Page Cache中的数据强制Flush到磁盘,但是Kafka并不建议使用。
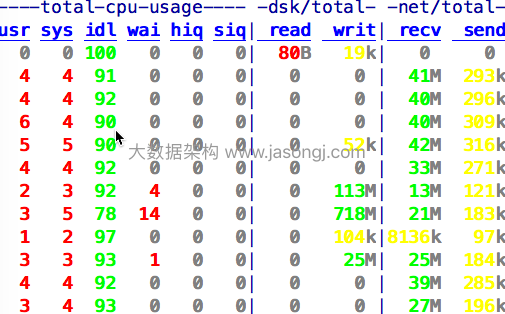
如果数据消费速度与生产速度相当,甚至不需要通过物理磁盘交换数据,而是直接通过Page Cache交换数据。同时,Follower从Leader Fetch数据时,也可通过Page Cache完成。下图为某Partition的Leader节点的网络/磁盘读写信息。
{kind=link}
从上图可以看到,该Broker每秒通过网络从Producer接收约35MB数据,虽然有Follower从该Broker Fetch数据,但是该Broker基本无读磁盘。这是因为该Broker直接从Page Cache中将数据取出返回给了Follower。
支持多Disk Drive
Broker的log.dirs配置项,允许配置多个文件夹。如果机器上有多个Disk Drive,可将不同的Disk挂载到不同的目录,然后将这些目录都配置到log.dirs里。Kafka会尽可能将不同的Partition分配到不同的目录,也即不同的Disk上,从而充分利用了多Disk的优势。
零拷贝
Kafka中存在大量的网络数据持久化到磁盘(Producer到Broker)和磁盘文件通过网络发送(Broker到Consumer)的过程。这一过程的性能直接影响Kafka的整体吞吐量。
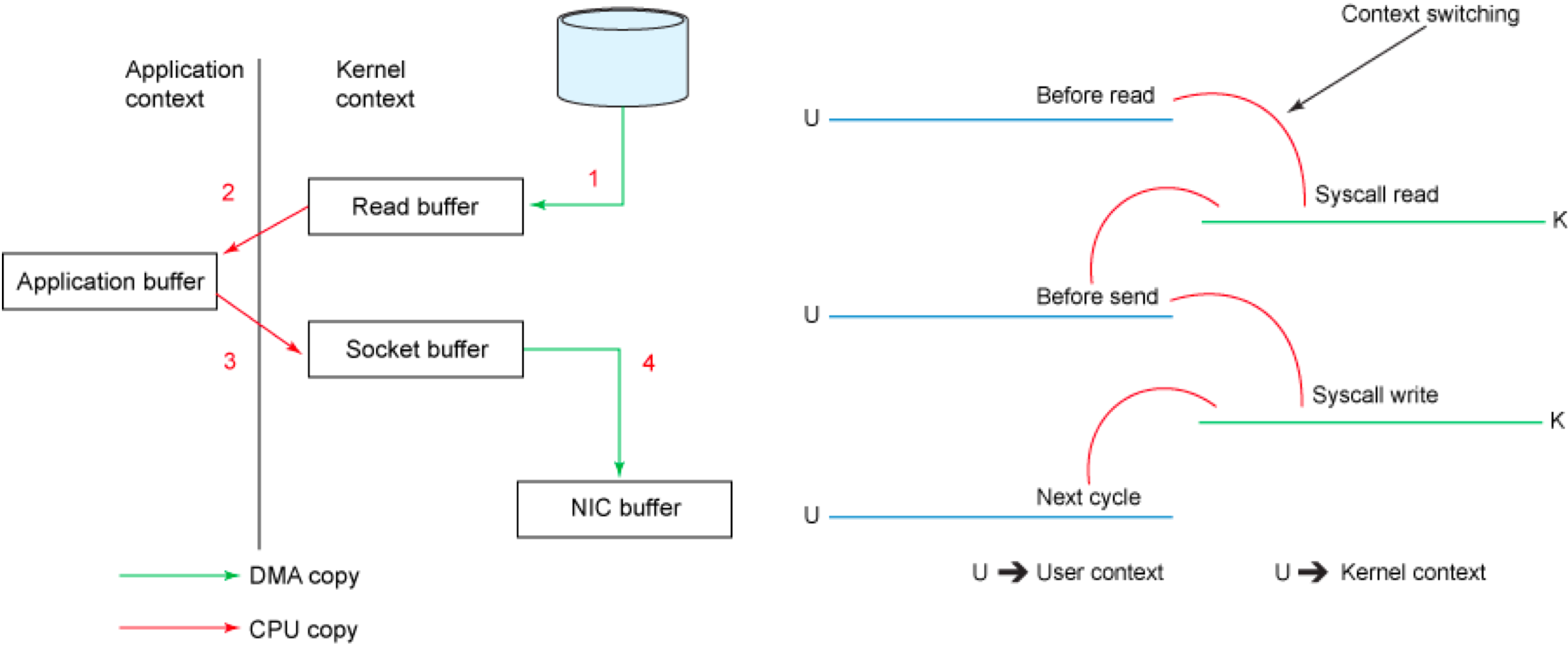
传统模式下的四次拷贝与四次上下文切换
以将磁盘文件通过网络发送为例。传统模式下,一般使用如下伪代码所示的方法先将文件数据读入内存,然后通过Socket将内存中的数据发送出去。
1 | buffer = File.read |
这一过程实际上发生了四次数据拷贝。首先通过系统调用将文件数据读入到内核态Buffer(DMA拷贝),然后应用程序将内存态Buffer数据读入到用户态Buffer(CPU拷贝),接着用户程序通过Socket发送数据时将用户态Buffer数据拷贝到内核态Buffer(CPU拷贝),最后通过DMA拷贝将数据拷贝到NIC Buffer。同时,还伴随着四次上下文切换,如下图所示。
{kind=link}
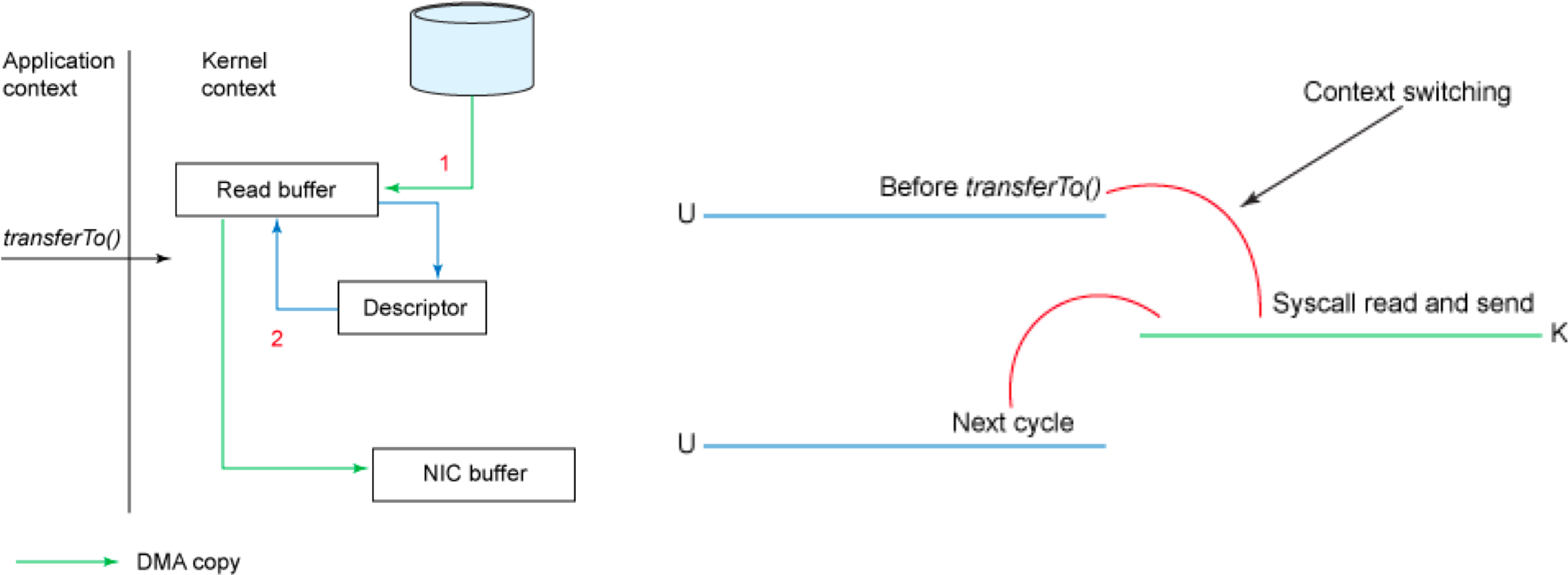
sendfile和transferTo实现零拷贝
Linux 2.4+内核通过sendfile系统调用,提供了零拷贝。数据通过DMA拷贝到内核态Buffer后,直接通过DMA拷贝到NIC Buffer,无需CPU拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件-网络发送由一个sendfile调用完成,整个过程只有两次上下文切换,因此大大提高了性能。零拷贝过程如下图所示。
{kind=link}
从具体实现来看,Kafka的数据传输通过TransportLayer来完成,其子类PlaintextTransportLayer通过Java NIO的FileChannel的transferTo和transferFrom方法实现零拷贝,如下所示。
1 | @Override |
注: transferTo和transferFrom并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供sendfile这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
减少网络开销
批处理
批处理是一种常用的用于提高I/O性能的方式。对Kafka而言,批处理既减少了网络传输的Overhead,又提高了写磁盘的效率。
Kafka 0.8.1及以前的Producer区分同步Producer和异步Producer。同步Producer的send方法主要分两种形式。一种是接受一个KeyedMessage作为参数,一次发送一条消息。另一种是接受一批KeyedMessage作为参数,一次性发送多条消息。而对于异步发送而言,无论是使用哪个send方法,实现上都不会立即将消息发送给Broker,而是先存到内部的队列中,直到消息条数达到阈值或者达到指定的Timeout才真正的将消息发送出去,从而实现了消息的批量发送。
Kafka 0.8.2开始支持新的Producer API,将同步Producer和异步Producer结合。虽然从send接口来看,一次只能发送一个ProducerRecord,而不能像之前版本的send方法一样接受消息列表,但是send方法并非立即将消息发送出去,而是通过batch.size和linger.ms控制实际发送频率,从而实现批量发送。
由于每次网络传输,除了传输消息本身以外,还要传输非常多的网络协议本身的一些内容(称为Overhead),所以将多条消息合并到一起传输,可有效减少网络传输的Overhead,进而提高了传输效率。
从零拷贝章节的图中可以看到,虽然Broker持续从网络接收数据,但是写磁盘并非每秒都在发生,而是间隔一段时间写一次磁盘,并且每次写磁盘的数据量都非常大(最高达到718MB/S)。
数据压缩降低网络负载
Kafka从0.7开始,即支持将数据压缩后再传输给Broker。除了可以将每条消息单独压缩然后传输外,Kafka还支持在批量发送时,将整个Batch的消息一起压缩后传输。数据压缩的一个基本原理是,重复数据越多压缩效果越好。因此将整个Batch的数据一起压缩能更大幅度减小数据量,从而更大程度提高网络传输效率。
Broker接收消息后,并不直接解压缩,而是直接将消息以压缩后的形式持久化到磁盘。Consumer Fetch到数据后再解压缩。因此Kafka的压缩不仅减少了Producer到Broker的网络传输负载,同时也降低了Broker磁盘操作的负载,也降低了Consumer与Broker间的网络传输量,从而极大得提高了传输效率,提高了吞吐量。
高效的序列化方式
Kafka消息的Key和Payload(或者说Value)的类型可自定义,只需同时提供相应的序列化器和反序列化器即可。因此用户可以通过使用快速且紧凑的序列化-反序列化方式(如Avro,Protocal Buffer)来减少实际网络传输和磁盘存储的数据规模,从而提高吞吐率。这里要注意,如果使用的序列化方法太慢,即使压缩比非常高,最终的效率也不一定高。Kafka设计解析(六)- Kafka高性能架构之道
原文地址:https://www.cnblogs.com/doit8791/p/11329440.html
- 黑产用“未来武器”破解验证码,打码小工都哭了
- Docker Registry v2 配置文件详解
- 在生产环境使用 Docker
- Docker 相关概念总览
- Docker 远程连接 -- dockerd 命令详解
- 在开发环境使用 Docker
- Docker Cloud 简介
- 一封伪造邮件引发的“探索”(涉及钓鱼邮件、SPF和DKIM等)
- Docker 镜像多阶段构建
- 利用WCF改进文件流传输的三种方式
- 利用系统特性伪装成一个免密登陆后门
- Docker 桌面版支持 kubernetes
- OOB(out of band)分析系列之DNS渗漏
- VLC播放器加载恶意字幕文件导致执行任意代码漏洞分析与POC实现
- JavaScript 教程
- JavaScript 编辑工具
- JavaScript 与HTML
- JavaScript 与Java
- JavaScript 数据结构
- JavaScript 基本数据类型
- JavaScript 特殊数据类型
- JavaScript 运算符
- JavaScript typeof 运算符
- JavaScript 表达式
- JavaScript 类型转换
- JavaScript 基本语法
- JavaScript 注释
- Javascript 基本处理流程
- Javascript 选择结构
- Javascript if 语句
- Javascript if 语句的嵌套
- Javascript switch 语句
- Javascript 循环结构
- Javascript 循环结构实例
- Javascript 跳转语句
- Javascript 控制语句总结
- Javascript 函数介绍
- Javascript 函数的定义
- Javascript 函数调用
- Javascript 几种特殊的函数
- JavaScript 内置函数简介
- Javascript eval() 函数
- Javascript isFinite() 函数
- Javascript isNaN() 函数
- parseInt() 与 parseFloat()
- escape() 与 unescape()
- Javascript 字符串介绍
- Javascript length属性
- javascript 字符串函数
- Javascript 日期对象简介
- Javascript 日期对象用途
- Date 对象属性和方法
- Javascript 数组是什么
- Javascript 创建数组
- Javascript 数组赋值与取值
- Javascript 数组属性和方法
- DFS&BFS - 52. N-Queens II
- DFS&BFS - 51. N-Queens
- maze - dfs
- DFS&BFS - 130. Surrounded Regions
- Tree - 145. Binary Tree Postorder Traversal
- Tree - 94. Binary Tree Inorder Traversal
- Tree - 144. Binary Tree Preorder Traversal
- grpc调用主要流程分析(一)
- Array - 42. Trapping Rain Water Hard
- Go modules 简介
- Spring事务的传播行为
- String - 71. Simplify Path
- 性能测试工具——wrk
- String - 67. Add Binary
- Math - 50. Pow(x, n)