Scrapy核心组件解析
时间:2019-04-16
本文章向大家介绍Scrapy核心组件解析,主要包括Scrapy核心组件解析使用实例、应用技巧、基本知识点总结和需要注意事项,具有一定的参考价值,需要的朋友可以参考一下。
{kind=link}
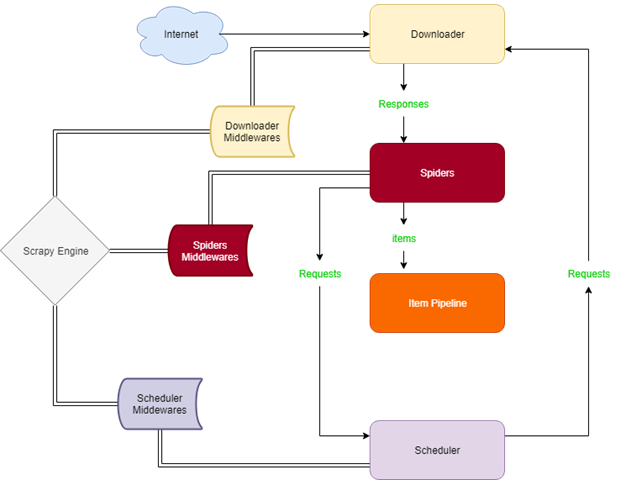
如图,分别是引擎(Engine),管道(Pipeline),调度器(Scheduler),下载器(Downloader),爬虫文件(Spider)以及一些中间件(Middleware)。
引擎是整个框架的核心,整个爬取的流程就是引擎来管理。调度器用来接收引擎发过来的requests,并在引擎再次请求的时候返回。调度器用来决定抓取的URL。下载器用来下载内容然后返回给爬虫,它是建立在twisted这个高效的异步模型上的。爬虫主要是一些逻辑代码,用于提取出我们需要的信息,也就是所谓的实体Item。管道负责处理实体内容,一般的功能有持久化存储,验证有效性,清楚无关信息等。
一次简单的大致scrapy爬起流程如下:
首先引擎将爬虫文件的url获取,提交给调度器。下载数据后,调度器通过引擎来将response交给下载器。下载好的数据会通过引擎交给爬虫文件,然后解析数据。最后爬虫文件将解析好的数据交给管道来进行处理。
{kind=link}
- HDUOJ---1867 A + B for you again
- HDUOJ--------1420Prepared for New Acmer
- PowerVM虚拟化环境下 CPU 利用率的监控与探究
- 虚函数中构造函数的调用顺序
- HDUOJ-----4512吉哥系列故事——完美队形I(LCIS)
- go语言mongdb管道使用(二)
- HDUOJ--4565 So Easy!
- Go 语言Map(集合)
- 简单的java实验,涉及到 类继承以及接口问题,方法体的重写(区别于重载)
- java 快速求素数
- 狄斯奎诺(dijkstra 模板)
- HDUOJ---汉洛塔IX
- 小错误系列
- HDUOJ-----4510 小Q系列故事——为什么时光不能倒流
- JavaScript 教程
- JavaScript 编辑工具
- JavaScript 与HTML
- JavaScript 与Java
- JavaScript 数据结构
- JavaScript 基本数据类型
- JavaScript 特殊数据类型
- JavaScript 运算符
- JavaScript typeof 运算符
- JavaScript 表达式
- JavaScript 类型转换
- JavaScript 基本语法
- JavaScript 注释
- Javascript 基本处理流程
- Javascript 选择结构
- Javascript if 语句
- Javascript if 语句的嵌套
- Javascript switch 语句
- Javascript 循环结构
- Javascript 循环结构实例
- Javascript 跳转语句
- Javascript 控制语句总结
- Javascript 函数介绍
- Javascript 函数的定义
- Javascript 函数调用
- Javascript 几种特殊的函数
- JavaScript 内置函数简介
- Javascript eval() 函数
- Javascript isFinite() 函数
- Javascript isNaN() 函数
- parseInt() 与 parseFloat()
- escape() 与 unescape()
- Javascript 字符串介绍
- Javascript length属性
- javascript 字符串函数
- Javascript 日期对象简介
- Javascript 日期对象用途
- Date 对象属性和方法
- Javascript 数组是什么
- Javascript 创建数组
- Javascript 数组赋值与取值
- Javascript 数组属性和方法
- Python小工具之消耗系统指定大小内存的方法
- Thinkphp框架+Layui实现图片/文件上传功能分析
- PHP实现单例模式建立数据库连接的方法分析
- 解决Python2.7中IDLE启动没有反应的问题
- PHP中mysqli_get_server_version()的实例用法
- 在unittest中使用 logging 模块记录测试数据的方法
- 分享8个Laravel模型时间戳使用技巧小结
- 基于python实现名片管理系统
- 记一个OLED编程中文显示函数的坑(留意变量数据类型的范围)
- tp5框架基于Ajax实现列表无刷新排序功能示例
- 浅谈pycharm下找不到sqlalchemy的问题
- PHP实现常用排序算法的方法
- 利用Python实现原创工具的Logo与Help
- PHP+ajax实现上传、删除、修改单张图片及后台处理逻辑操作详解
- 浅谈python下tiff图像的读取和保存方法